The recent boardroom upheaval at ChatGPT creator OpenAI, which sent ripples through the tech industry and beyond, seems to have stemmed from a letter sent by some researchers before the shock ouster of co-founder and CEO Sam Altman.
The letter raised concerns about a potential AI breakthrough that could pose risk to humanity. The decision to remove Altman, who returned as CEO within five days of sacking, was reportedly influenced by this letter.
OpenAI is said to be working on a project called Q* (pronounced Q-Star), which has the capability to solve unfamiliar math problems. It is believed that Q* could mark a significant advancement in OpenAI's pursuit of artificial general intelligence (AGI), which is defined as autonomous systems outperforming humans in economically significant tasks.
Q* was able to solve some math problems given its enormous computational capacity.
Also read: What is Q-Star, the OpenAI software that may have led to Altman's ouster
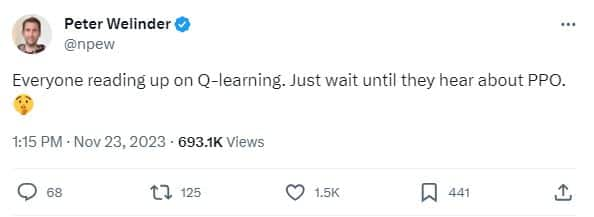
As the world speculates on the impact of this new model on AI (possibly based on Q-learning), Peter Welinder, OpenAI's vice president of product, hinted at another project the company has been working on since 2017.
In a recent post on X, Welinder said, "While everyone is diving into Q-learning, just wait until they learn about PPO."
Proximal Policy Optimization, or PPO, is a method in the world of AI that helps train computer models to make decisions in complicated or simulated situations.
"PPO has become the default reinforcement learning algorithm at OpenAI because of its ease of use and good performance," according to a research paper by the AI research lab.
PPO is like a personal trainer for computers, especially when they're learning by trial and error. Picture it as a helpful tool to teach machines how to produce text similar to human language.
The term "Proximal" suggests sticking closely to the original style, and "Policy Optimization" is about finding better strategies. By maintaining proximity to the original style, the improvements made by the programme are steady and reliable.
How does it work?Imagine you're helping a virtual student to write essays. PPO is like the coach that helps this virtual student get better at essay writing step by step.
Instead of making huge changes in one go, PPO encourages small and gradual improvements. This ensures that the virtual student's writing style doesn't drastically change from one essay to the next. It's like refining their skills little by little, without completely changing their writing style.
OpenAI uses PPO in different situations, like teaching computer programmes in simulated environments or getting better at challenging games.
PPO is great at these tasks because it's flexible and can handle situations where a programme needs to learn a series of actions to reach a goal. This makes it useful in areas like robotics and algorithmic trading.


Discover the latest Business News, Sensex, and Nifty updates. Obtain Personal Finance insights, tax queries, and expert opinions on Moneycontrol or download the Moneycontrol App to stay updated!
Find the best of Al News in one place, specially curated for you every weekend.
Stay on top of the latest tech trends and biggest startup news.