

Google is stepping up its efforts in fundamental artificial intelligence (AI) research aimed at helping people build more inclusive products and solutions in India, while also ensuring that global models reflect the country’s cultural diversity.
This research spans a range of real-world challenges in areas like agriculture, maternal health, patient care and disease treatment, cultural preservation, and language inclusion.
Researchers at Google DeepMind believe that by building for India's linguistic, economic, and cultural complexity, their work could lay the foundation for solutions that could benefit people globally.
“At Google, along with charting new frontiers in foundational AI, which forms the backbone of many of our launches in the Gemini era, we have continued advancing fundamental research that addresses some of the most pressing challenges facing humanity," said Manish Gupta, Senior Director for India and APAC at Google DeepMind.
"We’ve been inspired by the solutions India’s innovators have unlocked with these capabilities, demonstrating AI to be a powerful catalyst for multiplier impact and unprecedented effectiveness. We remain committed to growing this momentum, and enabling the benefits of helpful and inclusive AI to reach everyone across India," he added.
Agricultural monitoring and event detection
The company recently unveiled Agricultural Monitoring and Event Detection (AMED) API that leverages crop labels, raw satellite imagery and machine learning to assist crop monitoring and detection of agricultural events on fields across the country. It identifies 12 major crops which collectively account for more than 90 percent of the agricultural land in India.
The API, which is refreshed every 15 days, details the type of crop on individual fields across India, as well as each field's size and corresponding sowing and harvesting dates. It also provides historical information about the agricultural activity in each field for the last three years.
AMED API, developed by Google DeepMind and the Google Partnerships Innovation team, builds on the company's Agricultural Landscape Understanding (ALU) API, which was introduced last year and uses remote sensing and AI to provide landscape insights at individual farm level across India.
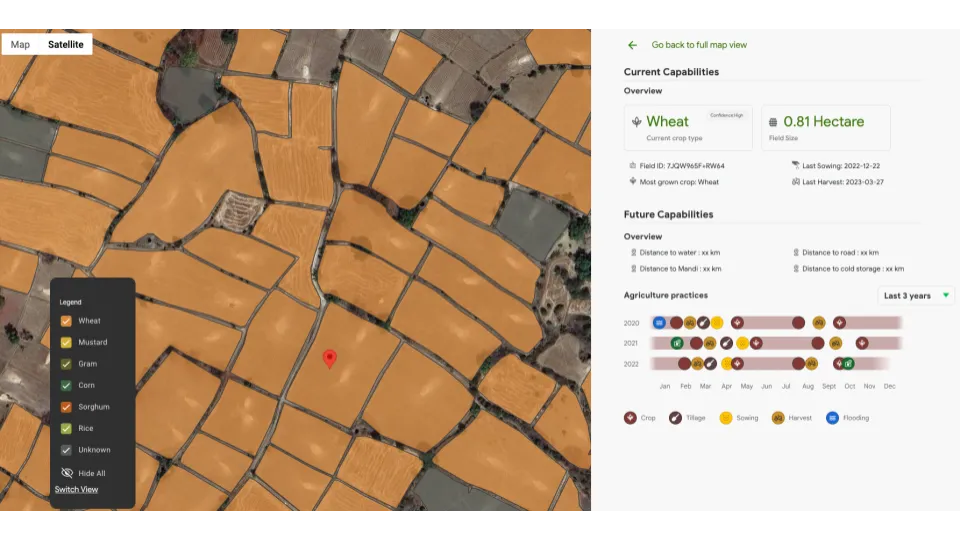 Agricultural Monitoring & Event Detection API (AMED API) developed by Google DeepMind and the Google Partnerships Innovation team (Image: Google)
Agricultural Monitoring & Event Detection API (AMED API) developed by Google DeepMind and the Google Partnerships Innovation team (Image: Google)
Researchers state that this information can help developers and the broader agricultural ecosystem build the next generation of AI-enabled solutions to improve agricultural management on farms. This includes addressing the specific needs of each crop, such as the right soil and water conditions, growing patterns, and climate requirements, as well as predicting harvest volumes.
"With AI research - and especially with AMED building on the foundation of ALU - we’re working on accelerating crucial shifts, transforming broad insights to granular, real-time data, so that increasingly impactful solutions not only translate into benefit for India’s farmers, but also bolster the nation against rising climate risks," said Alok Talekar, Lead, Agriculture and Sustainability Research Lead, Google DeepMind.
Talekar said the use cases unlocked by combining these two APIs are substantial. This includes offering loans, providing insurance, delivering advisories, or supplying agricultural inputs, all of which can now be done in a more proactive and informed manner.
TerraStack, a geospatial tech startup incubated at IIT-Bombay, has used ALU API to build a rural land intelligence system to support rural lending, land record modernization, and determine the vulnerability of farms to climate risk. It is now exploring AMED API for a rural lending use case.
“These APIs are helping standardise and transform previously unorganised and unusable data into solutions for one of India’s most critical sectors. They enable us to build solutions that ultimately benefit India’s farmers, reducing friction in their path to access tools and resources that support not just their livelihoods, but the sustainability of the country’s agriculture ecosystem,” said TerraStack co-founder Aaryan Dangi.
Read: Google's AI model to help researchers identify TB, other diseases from the sound of cough
Improved Indic tokenisation in Gemini 2.5
Google stated that it has also made progress in tokenisation for Indic languages in its most advanced AI model, Gemini 2.5, a move that could significantly reduce costs and improve efficiency.
Dr. Partha Talukdar, Language Research Lead at Google DeepMind, recently demonstrated that a sample Hindi text which previously required about 211 tokens in Gemini 1.5 can now be represented in just 134 tokens in Gemini 2.5. Tokens are units of text that AI models use to understand and process language.
These efficiency gains have also been extended to Google's Gemma open models, which have been leveraged by Bengaluru-based Sarvam AI for its translation model, Sarvam-Translate, built on top of Gemma 3. The open-weight model translates text across 22 Indian languages and is capable of handling diverse formats, contexts, and styles.
Read: Google licenses its AI model to help Indian firms detect early blindness in diabetic patients
5,000 hours of Indic language data
Project Vaani, a joint initiative by Google, the Indian Institute of Science (IISc), and AI & Robotics Technology Park (ARTPARK), has also released the first batch of open-source multimodal data from its second phase, comprising more than 5,000 hours from over 40 districts.
First announced in December 2022, Project Vaani aims to collect and transcribe anonymized, open-source speech data from all 773 districts of India, ensuring linguistic, educational, urban-rural, age, and gender diversity in three phases.
The initiative is expected to boost the development and benchmarking of a range of AI applications including automatic speech recognition (ASR) and Text-to-Speech (TTS) systems, speaker identification and verification, language identification, speech enhancement and filtering, and multimodal and multilingual large language models.
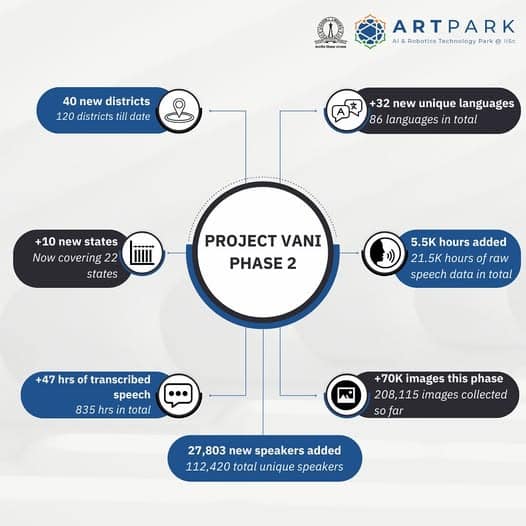 A snapshot of Project Vaani's Phase 2
A snapshot of Project Vaani's Phase 2
The first phase, which focused on 80 districts across 10 states, was completed last year with the release of over 14,000 hours of speech data across 58 languages.
With the latest release, nearly 21,500 hours of speech audio in 86 languages have been collected from over 112,000 speakers across 120 districts and 22 states, and made available on the Project Vaani website, the Indian government’s Bhashini platform, and the open-source AI repository Hugging Face. About 835 hours of speech has been transcribed until now.
Google has also developed a benchmark called CUBE (Cultural Benchmarking) to evaluate cultural competence of text-to-image models. It currently includes over 300,000 cultural artifacts across three domains (cuisine, landmarks, and art) associated with eight countries, including India.
Read: India well-positioned to help shape future of AI: Google DeepMind's Jeff Dean
Strengthening Indian language representation in global AI models
Google is also bringing its Amplify initiative to India as part of its efforts to improve the representation of Indian languages in AI models. The company is collaborating with researchers at IIT-Kharagpur to build structured, hyperlocal, and high-quality datasets that reflect the country’s rich linguistic and cultural diversity.
Launched a few years ago, Amplify aims to address knowledge gaps in large language models (LLMs) by incorporating localised data, including languages, dialects, and cultural nuances that are often missing from current AI training methods.
As part of the programme, Google's local partners collect and annotate data through a community-centric, expert-vetted process, while ensuring responsible practices, potential for bias, and appropriate annotation techniques are applied throughout the development process.
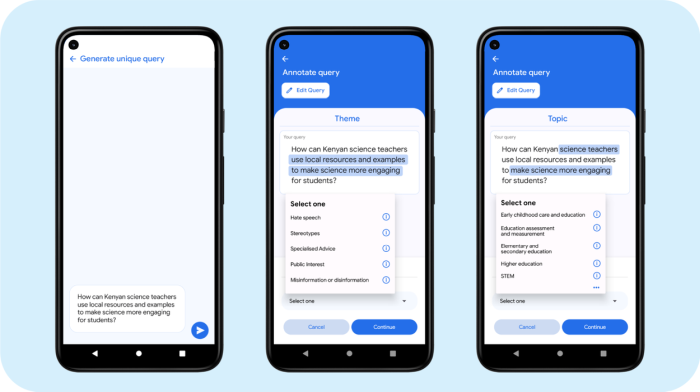 Amplify app with an example of an localised query and suggested annotations (Image: Google)
Amplify app with an example of an localised query and suggested annotations (Image: Google)
The initiative was first piloted in Sub-Saharan Africa, in partnership with Makerere University’s AI Lab in Uganda. During the pilot, it produced an annotated dataset of over 8,000 queries in seven African languages, created collaboratively with 155 experts, which covers a wide range of topics across domains such as health, culture, education, policy, and governance.
In India, researchers at IIT-Kharagpur, along with local sector experts, will begin building datasets on specific issues, including healthcare and safety, in multiple Indic languages, the company said.
"We're keen to identify knowledge gaps that exist across different issues. Local experts will use the app we've built to create and annotate datasets. Once it's complete, we'll make the dataset fully open source and available for anyone to explore," said Madhurima Maji, Lead Program Manager, Amplify Initiative for India at Google.
While the initiative bears some resemblance to Project Vaani, Maji said the key difference is that Amplify focuses on hyperlocal Indic languages, in whatever form or language it naturally occurs. Meanwhile, Project Vaani is "laser-focused on capturing Indian languages more broadly."
"We hope that AI systems coming forth will be slightly more culturally sensitive, better situated, and more aware of India's reality," she said.
Talukdar said partnerships through initiatives like Project Vaani and Amplify Initiative "fuel our continued investments in language and culture research, and drive us to make our foundational models, on which India is building its AI ambitions, more effective and efficient in processing Indian languages."
In addition to these initiatives, Google stated that over 150,000 researchers across India are now using the AlphaFold Protein Structure Database to tackle sensitive, long-standing medical challenges such as autoimmune diseases, cancer, and others. This is up from 91,000 users in May 2024.
Launched in 2021, the database was built using an AI system developed by Google DeepMind, for which Demis Hassabis and John Jumper, were recognised with a Nobel Prize last year. It offers researchers free access to more than 200 million predicted protein structures.



Discover the latest Business News, Sensex, and Nifty updates. Obtain Personal Finance insights, tax queries, and expert opinions on Moneycontrol or download the Moneycontrol App to stay updated!
Find the best of Al News in one place, specially curated for you every weekend.
Stay on top of the latest tech trends and biggest startup news.





