



RN Bhaskar
Meeting Prof Edward Altman was like a pilgrimage. For 25 years, I have looked at the Altman Z-score model with reverence. I became more familiar with the model when tweaking it and redesigning it with the help of two extremely bright Wharton graduates -- Chetan and Vinay Parikh -- in the late 1980s and early 1990s.
The model we had then developed was intended to do predict excellence in each industry (because each industry has a different set of dynamics under which it operates). It was quite the opposite of what the Z-score does which is to predict bankruptcy.
Each week, we used the model to determine the best performer in an industry segment for a large publishing group. We continued this from 1990 to 1998. Then I decided to leave the group. So did the Wharton geniuses. There was nobody left to understand the multi-variant discriminant analysis model and the exercise was scrapped.
But what we discovered in the fourth year was invaluable. Over 85 percent of the industry winners had outperformed the BSE Sensex. It had become an amazing investment model as well.
Prof Altman, who is Professor of Finance, Emeritus, at New York University's Stern School of Business has dedicated more than 50 years studying bankruptcy. He was in Mumbai recently, at the invitation of Assocham, to educate Indian bankers, credit rating agencies and investment managers about how the model works. He has also developed a new model -- Z double prime.
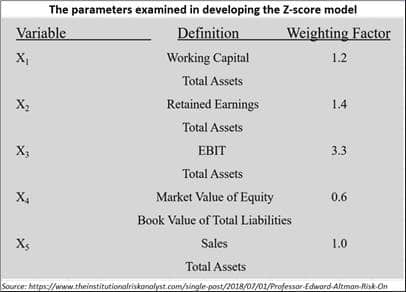
As Prof Altman puts it, “It was built in 1995… for non-manufacturers, even though it has assets among the variables it considers. We found Z double prime to be accurate for retailers. But I cannot really say it will be accurate for technology firms. However, this model is appropriate for retail, energy, services sector etc. It focusses on four variables rather than five. We eliminated the fifth variable -- ‘sales to total assets’.”
Altman is also in India to develop new models for the small and medium enterprise (SME) sector that would be both industry and region specific. As he puts it, “We have built models for the SME area in 19 European countries. We are now beginning to look at India because the need is urgent, and for the first time you have a good bankruptcy code, though it is early days yet.”
He sees a big problem in data collation, though. To develop the model, one needs a very large amount of data.
A layman’s guide to Z score
Typically, this data is divided into three clusters. One cluster would comprise around 100 companies that almost everyone agrees are good companies. Another set would comprise a similar number of companies that people reckon are bad companies. The rest of the companies would form the third (very large) cluster. A regression multi-variant regression analysis is then done in order to find out how the selected ratios explain the goodness or badness of each company. The ratios have to be tweaked till one gets a higher R square (the ratio which tells you whether the model is working well in determining the soundness of the companies). The higher the R square, the better is the way the model works.
But this is not possible unless data sizes are large.
That is why, explains Prof Altman, India uses this model to look at equity rather than debt. The data size of debt instruments in India is not large. As the debt market improves, you will find a greater application of this model for ranking debt too.
In India, for instance, his model was used to identify possible bankruptcy for at least 10 companies two years before the crisis finally hit home. This included companies like Essar Steel, Lanco, Bhushan Power & Steel, Alok Industries, Monet Ispat, Era Infra Engineering, Electrosteel, Amtek Auto, Jyoti Structures and IL&FS (see slides 26-35 here). Yet, as Prof Altman points out, credit ratings companies gave them investment grade rankings till a few months before the declaration of default.
“These ratings companies should be using this model more often,” he said.
Altman Z-score was developed in the 1960s. In its initial runs, the Altman Z-Score was found to be 72 percent accurate in predicting bankruptcy two years before the event. In subsequent versions, the model was found -- by 1999 -- to be approximately 80–90 percent accurate in predicting bankruptcy one year before the event. Though designed initially for manufacturing companies with assets of more than $1 million, it has now been modified in various ways to deal with smaller companies across all sectors. It is used by auditors, management accountants, courts, and database systems for loan evaluation.
But, as Prof Altman warns, “In case of assets-light companies like Uber, both models will be a problem. I don’t have an answer to that. I will have to build a separate model for technology companies like Airbnb, Uber and so on. Additionally, we would need a significantly large number of such companies before we build a separate model. We would also need defaults in this space to build the new model. I love defaults and bankruptcies. Not because I am a sadist but because I get data. I have said that over years. My model will not be appropriate for firms with less assets or no assets. I cannot do anything about it. “
But, as he points out, models for such sectors too will soon get developed. Today the number of such companies is very small. We need more companies; and bankruptcies. When bankruptcies occur, we can then analyse them better, and find out the tell-tale ratios that could have predicted the collapse.
Expect Prof Altman to be in the news more often in India.
The author is consulting editor with moneycontrol.com
Discover the latest Business News, Sensex, and Nifty updates. Obtain Personal Finance insights, tax queries, and expert opinions on Moneycontrol or download the Moneycontrol App to stay updated!
Find the best of Al News in one place, specially curated for you every weekend.
Stay on top of the latest tech trends and biggest startup news.



